|
|
有许多研究工作尝试将人工智能方法应用于网络安全领域,但AI方法的黑盒特性阻碍了其真正的落地应用。近几年,可解释AI(XAI)也成为网络安全领域的重点关注方向。
本文通过阅读以下论文,对这个领域有一个大体的梳理和把握。针对GNN模型可解释性方法相关工作的梳理见《GNN可解释性方法总结》。
- [1] Explainable Artificial Intelligence for Cyber Threat Intelligence (XAI-CTI)
- [2] Explainable Artificial Intelligence in Cybersecurity: A Brief Review
- [3] Explainable Artificial Intelligence Applications in Cyber Security: State-of-the-Art in Research
- [4] Explainable Artificial Intelligence in CyberSecurity: A Survey
- [5] Explainable machine learning in cybersecurity: A survey
- [6] SoK: Explainable Machine Learning for Computer Security Applications(实验室主页Cyber Analytics Lab)
- [7] Evaluating Explanation Methods for Deep Learning in Security,EuroS&P‘20(网站及代码https://github.com/alewarne/explain-mlsec)
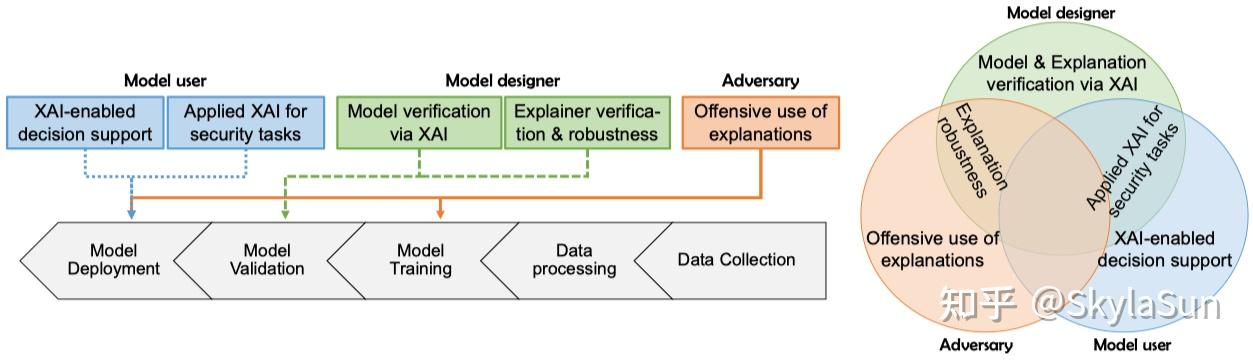
安全领域不同角色下XAI应用场景[6]
XAI分类方式
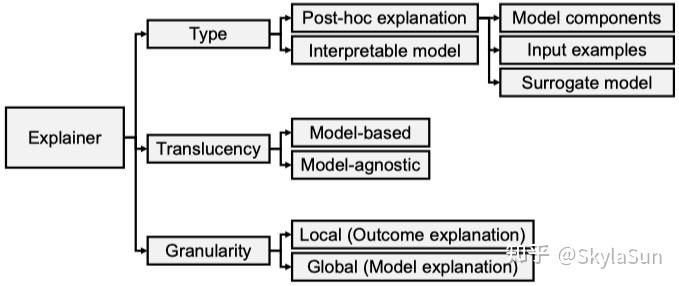
XAI分类方法[6]
内在的(intrinsic/transparent)和事后的(post-hoc/extrinsic)。前者关注模型训练和执行阶段,将决策规则、注意力机制、推理路径、掩码、与或图等技术结合到模型中。而且, 如线性模型、SVM、决策树、XGBoost等天生就具有较强的可解释性。随着术语的规范这类模型也被称为“interpretable”。后者则在模型收敛后解释其中的各个组件,应用较多的是模型无关(model-agnostic)的方法,包括可视化、反事实分析、代理模型、概念重要性、LIME、SHAP等技术。
模型有关的(model-specific)或模型无关的(model-agnostic)。后者通常分析特征、输入、输出等部分,理论上可以在不访问模型内部信息的情况下,应用于任何ML模型。
本地的(local)或全局的(global)。前者只解释针对单个数据样本的香味,后者解释整个模型的所有行为。
可解释性方法的结果输出形式包括:文本、可视化、模型内部工作逻辑、论据(arguments)等。
常见XAI框架包括LIME, SHAP, Anchors, LORE, CRAD-CAM, CEM等。除CRAD-CAM外,其它都属于[本地、事后、模型无关]的解释方法,CRAD-CAM为[本地、事后、模型相关]。
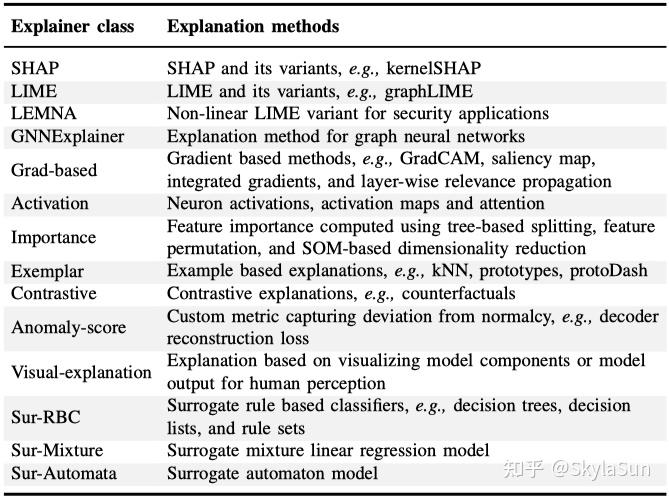
常用XAI方法汇总[6]
经典网络安全领域XAI研究
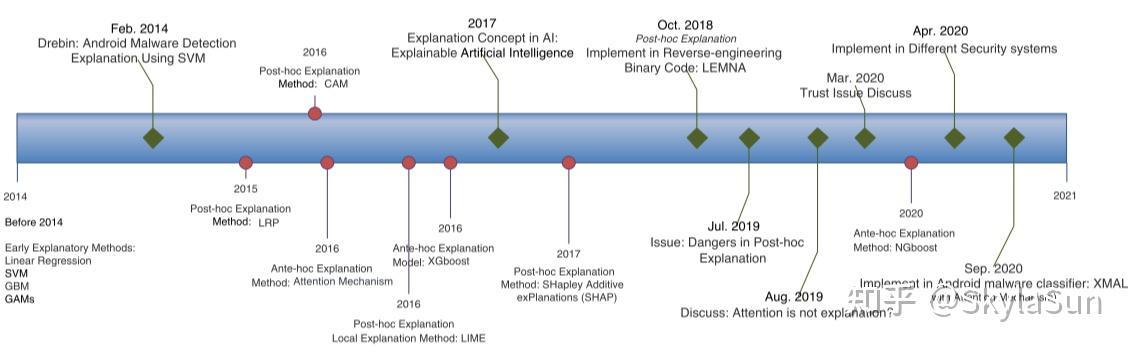
安全领域ML可解释性发展路线[5]
通用框架
- Lemna: Explaining deep learning based security applications,CCS’18
- Deepaid: interpreting and improving deep learning-based anomaly detection in security applications,CCS‘21
- CADE : Detecting and explaining concept drift samples for security applications,US’21
恶意软件检测(Malware)
- Explaining Black-box Android Malware Detection, EUSIPCO'18;
- Explaining AI for Malware Detection: Analysis of Mechanisms of MalConv, IJCNN'20
- Effective detection of mobile malware behavior based on explainable deep neural network, Neurocomputing'21
- Towards an interpretable deep learning model for mobile malware detection and family identification, C&S'21
- Can We Trust Your Explanations? Sanity Checks for Interpreters in Android Malware Analysis, TIFS’21
钓鱼、垃圾邮件及欺诈检测(Phishing & Spam & Fraud)
- An Explainable MultiModal Hierarchical Attention Model for Developing Phishing Threat Intelligence, TDSC'22
- Phishing Email Detection Using Persuasion Cues, TDSC'22
- Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages,US'21
- Explainable Machine Learning for Fake News Detection, '19
- Explainable Machine Learning for Fraud Detection, '21
- xFraud: Explainable Fraud Transaction Detection, '21
僵尸网络检测
- Subspace Clustering for Interpretable Botnet Traffic Analysis, ICC'19
- Detection and Classification of Botnet Traffic using Deep Learning with Model Explanation, TDSC'22
- BotStop : Packet-based efficient and explainable IoT botnet detection using machine learning, '22
- First Step Towards EXPLAINable DGA Multiclass Classification. '21
- Interpretability evaluation of botnet detection model based on graph neural network, infocom W‘22
网络入侵检测
- Achieving explainability of intrusion detection system by hybrid oracle-explainer approach,IJCNN'20
- An Explainable AI-Based Intrusion Detection System for DNS Over HTTPS (DoH) Attacks, TIFS'22
- EXPLAIN-IT: Towards explainable AI for unsupervised network traffic analysis, CoNext'19
- ROULETTE: A neural attention multi-output model for explainable network intrusion detection, '22
常用效果评估指标
描述准确性(descriptive accuracy,DA),反映解释方法捕捉相关特征的准确程度。实验中采取间接测量的手段,即观察删除最相关的top K特征后模型预测结果会出现多大程度的改变。
描述稀疏性(descriptive sparsity,DS),反映了解释方法是否可以有效区分不同维度的特征信息。需要注意的是,DS与DA并不相关,需要全面衡量。
完整性(completeness),即可以在所有可能的情况下产生合理的解释结果而不出现退化(零解释的情况)。
稳定性(stability),某方法多次运行后生成的解释结果大致保持一致。而实际情况是,大多数黑盒解释方法基于随机扰动运行,可能导致相同输入下的不同结果。
效率(efficiency),在处理大量数据时,可以在合理的时间给出解释结果。
鲁棒性(robustness),在安全领域,可解释性方法可能会受到对抗扰动影响,返回不相关信息。 |
|



 发表于 2022-11-30 17:10:53
发表于 2022-11-30 17:10:53